看到论坛有人讨论这个,就蛋疼的写了个科普文章,文章逻辑有点乱,将就着看吧。
一提到 asa、asp 后缀的 Access 数据库(.mdb),都知道数据库插马,都知道 Unicode 编码的一句话……
插你妹啊……,又有几个知道原理?从06年至今又有几个人仔细研究过,恭喜你了,“工具黑客”你们好……
注意:这里讨论的是没有开启 Unicode 压缩的情况下,为什么不是开启了的情况下??靠,再次插你妹!都开启了,直接写ANSI格式的一句话就行了,压根不存在这个问题。。。还讨论个毛!
正文开始……
|
引用 lake2 的文章“ASP数据库插马小议”,2006-05-02 11:05: 随着技术的发展,ASP数据库插马也不是什么新鲜的东东了,相信阁下也玩过这个的吧。呵呵,那你有没有遇到过插入的asp代码被空格拆开的情况呢(即插入的每个字符之间都出现了空格)?现在,就让我们来解决这个问题。 经过对多例实际情况的分析,我发现只要出现代码被空格隔开的数据库,相应的字段的Unicode压缩属性总是“否”。相反,如过Unicode压缩属性为“是”,则可以通过该字段进行插马。 经过搜索,发现微软官方对Unicode压缩的描述:“Microsoft Access 2000 或更高版本使用 Unicode 字符编码方案来表示文本、备注和超链接字段中的数据。Unicode 将每个字符表示为两个字节……需要的存储空间比在 Access 97 或更早版本中要多……可通过将“文本”、“备注”或“超链接”字段的“Unicode 压缩”属性的默认值设为“是”来弥补 Unicode 字符表达方式所造成的影响” 哦,原来开启了 Unicode 压缩的话,数据库会自动把拉丁字符(西欧语言如英语、西班牙语或德语)用1个字节来存储;如果没开启,数据库就会用2个字节(1个字节为0x00,作为文本将被自动转换为空格)存储拉丁字符,也就造成了插入的asp代码被空格隔开的情况。 那么,在这种情况下如何插马呢? 突破口就在 Unicode 压缩那儿,既然数据库不给我们压缩,那么就让我们自己来压缩吧。很简单,就是把asp代码先转化为 Unicode 然后再插入数据库。我用VB写了个小软件来实现这个功能,注意由于转换的时候容易产生不可显示的字符(将会出现?),所以要精心构造代码咯,当然你也可以捡便宜用图中那个我构造的^_^ 对VB来说,转换之后的代码的长度已经减少一半,嘿嘿,那这个可不可以说是对最小的ASP后门的一种突破呢? 程序可在这里下载之:http://www.0x54.org/lake2/program/a2u4hack.exe,呵呵,Enjoy It ! |

这是将 ansi 编码的一句话以 unicode 方式显示,由于 Access 相应的字段的 Unicode 压缩属性为“否”,所以Access不会对你的数据做任何处理就保存为文件,所以在文件中它会“还原为”原 ansi 编码的一句话的内容,所以就可以解析执行了。
编码原理很简单:
| Text2.Text = StrConv(Text1.Text, vbFromUnicode) Text1.Text = StrConv(Text2.Text, vbUnicode) |
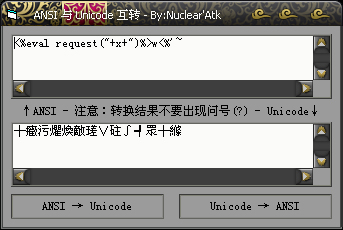
ANSI 与 Unicode 互转 - ANSI 编码的一句话以 Unicode 方式显示
编译好的:http://115.com/file/e6e0lsk7
就这两行代码,就行了,就实现了互转。。。。。
最早出自于 lake2 的文章“ASP数据库插马小议”,可能比这还早,我上次研究的时候,发现早在 04、05 年就有人写相关文章了,只不过那时是不存在这个编码问题,编码过的是从他这里才开始发扬光大了。
如果对编码转换不太了解的同学,可能难以理解,这个“转换”过程有点抽象,过程如下:
首先简单的介绍一下这两种编码方式,unicode和ansi都是字符代码的一种表示形式。
ANSI 格式,简单来说就是普通的英文字母符号和数字,使用1-2个字节储存字符(英文字母、数字、及标点符号使用1个字节,汉字2个字节),不同的国家和地区制定了不同的标准。
Unicode 格式,是中文和其他文种也包括英文的统一码,unicode 可以是两个字节或是4个字节,现在使用的一般是2字节的,这也就是为什么同样的内容,而Unicode编码体积比较大的原因。
在 Access 中,如果开启了 Unicode 压缩的话,数据库会自动把拉丁字符(西欧语言如英语、西班牙语或德语)用1个字节来存储;
如果没开启,数据库就会用2个字节(1个字节为0x00,作为文本将被自动转换为空格)存储拉丁字符,也就造成了插入的asp代码被空格隔开的情况。
现在我有一串ANSI编码的字符串:a = "abcd",然后我把这个字符串当做“Unicode 编码的字符串”,虽然它是ANSI编码的。
然后将它转换为ANSI编码的,然后显示出来。显示的内容便是:扡摣,也就是你看到的那串“乱码”。
重点就在这里了,这也就是为什么不能出现问号的原因(?)。
因为按照这种“伪转换”的方式,有部分相邻ANSI字符无法转换,结果就会出现问号(编码失败)。
为什么是相邻的字符?这个就是ANSI编码和Unicode编码的重要区别了。
因为ANSI用的1-2字节,而Unicode用的2字节,所以在前边进行伪转换的时候就产生了“位数差”。
由于存在位数差,所以当进行伪转换时,"ab"这两个字符会合并成一个Unicode字符,即 Hex:6161。
6161 这个 Hex 值就是汉字“扡”的 Unicode 编码,也就是说这个伪转换根本就没有进行任何字符转换,而只是简单地将两个ANSI字符的值,“合并”为一个Unicode字符的值。
那为什么会产生问号?因为Unicode的两个字节是有个范围的,很多ANSI字符合并后会超过这个范围。
例如字符:(++) = Hex(2B2B),而“2B2B”超过了Unicode的范围,所以没法“显示”了,显示为问号。
这也是为什么汉字更不能进行伪转换的原因了,所以这种“伪转换”方式只支持英文字符、标点符号和数字,当然,你的字符串长度也必须为偶数。
有点绕口,可能有的同学不好理解,多消化就好了……
然后把转换后的“乱码”,放入到Access数据库的时候,由于相应的字段的Unicode压缩属性为“否”,所以Access不会对你的数据做任何处理就保存为文件。
所以当你用文本打开的时候,这时候为ANSI编码模式,你阅读到的内容就是原来的“abcd”,当然,IIS也会阅读为“abcd”,所以就成功解析了。
最简单的伪转换方式:
1、打开记事本或写字板,随便输入字符,例如:abcd
2、将文本保存为ANSI编码的文件。
3、使用十六进制编辑器打开这个文件。
4、在文件最开始添加两个字节,值为:FFFE,然后保存。FFFE是一个“文件头”,告诉记事本,这个文件使用的Unicode编码。
5、现在使用记事本打开此文本文件,你会看到乱码,也就是“伪编码”后的内容。
也就是说这整个“伪编码”,根本没有改动任何内容,只是用Unicode编码方式显示ANSI编码的字符。
为什么不能直接写进去Unicode编码的字符?因为那样的话,你保存到文件里的还是Unicode字符,完全就等于Unicode压缩功能开启的模式,文件中还是Unicode编码字符,自然不能解析了。
相关文章:
让LOOP防下载形同虚设直接拿Shell:https://lcx.cc/post/1847/
ASP数据库插马小议:http://blog.csdn.net/lake2/article/details/705362